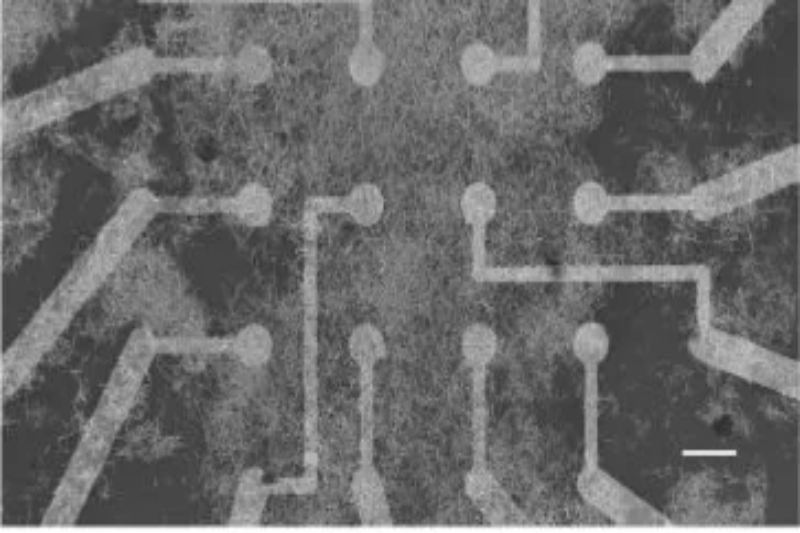
A group of specialists with the Colleges of California and Sydney has looked to evade the gigantic power utilization of fake brain networks through the production of a new, silver nanowire-based approach. Because of the properties of silver nanowire – nanostructures around one-thousandth the width of a human hair – and the closeness of its organizations with those present in natural computer chips (minds), the exploration group had the option to construct a neuromorphic gas pedal that outcomes in much lower energy utilization in computer based intelligence handling undertakings. The work has been distributed in the diary Nature Correspondences.
Nanowire Organizations (NWNs) investigate the emanant properties of nanostructured materials – think graphene, XMenes, and other, for the most part still being worked on innovations – because of the manner in which their nuclear shapes normally have a brain network-like actual design that is essentially interconnected and has memristive components. Memristive as in it has structures that can both change their example because of an upgrade (for this situation, power) and keep up with that design when that boost is gone, (for example, when you press the Off button).
The paper additionally makes sense of how these nanowire networks (NWNs) “likewise show mind like aggregate elements (e.g., stage changes, switch synchronization, torrential slide criticality), coming about because of the interchange between memristive exchanging and their intermittent organization structure”. This means these NWNs can be utilized as processing gadgets, since inputs deterministically incite changes in their association and electro-substance bond hardware (similar as a guidance being sent towards a x86 computer chip would bring about a fountain of unsurprising tasks).
Learning Progressively
Nanowire Organizations and other RC-adjusted arrangements likewise open an essentially significant capacity for man-made intelligence: that of persistent, unique preparation. While computer based intelligence frameworks of today require extended times of information approval, parametrization, preparing, and arrangement between various “variants”, or clusters, (for example, Visit GPT’s v3.5 and 4, Human-centered’s Claude and Claude II, Llama, and Llama II), RC-centered figuring approaches, for example, the specialist’s silver NWN open the capacity to both get rid of hyper-parametrization, and to open versatile, steady difference in their insight space.
This intends that with each new piece of information, the general framework loads adjust: the organization learns without being prepared and retrained on similar information, again and again, each time we need to control it towards value. Through the internet learning, dynamic transfer of-information approach, the silver NWN had the option to help itself to perceive written by hand digits, and to review the beforehand perceived transcribed digits from a given example.
Once more exactness is a necessity however much speed is – results should be provable and deterministic. As indicated by the scientists, their silver-based NWN exhibited the capacity to succession memory review undertakings against a benchmark picture acknowledgment task utilizing the MNIST dataset of manually written digits, hitting a general precision of 93.4%. Analysts characteristic the “generally high arrangements exactness” estimated through their internet learning strategy to the iterative calculation, in light of recursive least squares (RLS).
The Organic Huge Move
Assuming that there’s one region where organic handling units actually are miles in front of their counterfeit (engineered) partners, it is energy effectiveness. As you read these words and explore the web and pursue groundbreaking choices, you are consuming far less watts (around 20 W) to process and control, to work, on those ideas than even the world’s most power-effective supercomputers.
One justification for this is that while fixed-capability equipment can be coordinated into our current simulated intelligence speed increase arrangements (read, Nvidia’s almighty market predominance with its A100 and H100 item families), we’re actually adding that fixed-capability equipment onto a major class of chips (profoundly equal yet halfway controlled GPUs).
Maybe it’s valuable to think about it along these lines: any issue has various arrangements, and these arrangements all exist inside what could be compared to a computational inflatable. The arrangement space itself psychologists or builds as per the size and nature of the inflatable that holds it.
Current simulated intelligence handling basically imitates the confounding, 3D guide of potential arrangements (through melded memory and handling groups) that are our neurons onto a 2D Turing machine that should squander unimaginable measures of energy essentially to spatially address the jobs we want to fix – the arrangements we really want to find. Those necessities normally increment with regards to exploring and working on that arrangement space proficiently and precisely.
This major energy effectiveness limit – one that can’t be amended simply through assembling process upgrades and sharp power-saving advancements – is the justification for why elective simulated intelligence handling plans (like the simple and-optical ACCEL, from China) have been showing significant degrees further developed execution and – in particular – energy productivity than the current, on-the-racks equipment.
One of the advantages of utilizing neuromorphic nanowire networks is that they are normally adroit at running Repository Registering (RC) – a similar method utilized by the Nvidia A100 and H100s of today. Yet, while those cards should reenact a climate (they are fit for running an algorithmic imitating of the 3D arrangement space), carefully designed NWNs can run those three-layered registering conditions locally – a strategy that massively lessens the responsibility for simulated intelligence handling errands. Supply Figuring makes it so that preparing doesn’t need to manage coordinating any recently added data – it’s consequently handled in a learning climate.
What’s in store Shows up Sluggish
This is the main detailed case of a Nanowire Organization being tentatively gone against a laid out AI benchmark – the space for disclosure and improvement is subsequently still enormous. As of now, the outcomes are very reassuring and point towards a changed methodology future towards opening Repository Registering capacities in different mediums. The actual paper depicts the likelihood that parts of the web based learning skill (the capacity to coordinate new information as it is gotten without the expensive necessity of retraining) could be carried out in a completely simple framework through a cross-point cluster of resistors, rather than applying a carefully bound calculation. So both hypothetical and materials configuration space actually covers various potential, future investigation scenes.
The world is eager for computer based intelligence speed increase, for Nvidia A100s, and for AMD’s ROCm rebound, and Intel’s step onto the conflict. The prerequisites for artificial intelligence frameworks to be sent in the way we are presently exploring towards – across Superior Execution Figuring (HPC), cloud, individualized computing (and customized game turn of events), edge registering, and exclusively free, barge-like country states will just increment. It’s impossible these necessities can be supported by the 8x man-made intelligence derivation execution enhancements Nvidia promoted while hopping from its A100 gas pedals towards its understocked and authorized H100 present. Taking into account that ACCEL guaranteed 3.7 times the A100’s exhibition at much improved effectiveness, it sounds precisely perfect opportunity to begin looking towards the following enormous presentation leap forward – how long into the future that might be.

















 Entertainment4 weeks ago
Entertainment4 weeks ago
 Entertainment3 weeks ago
Entertainment3 weeks ago
 Entertainment3 weeks ago
Entertainment3 weeks ago
 Entertainment3 weeks ago
Entertainment3 weeks ago
 Entertainment3 weeks ago
Entertainment3 weeks ago
 Entertainment3 weeks ago
Entertainment3 weeks ago
 Uncategorized4 weeks ago
Uncategorized4 weeks ago
 Entertainment3 weeks ago
Entertainment3 weeks ago